

In this series I’m building courseware (teaching software) to let folks go through lessons in a better way than the simple email classes I use now. Last week we figured out how to track progress for a user in a topic using an AJAX call hooked up to a button and selector in the browser. It looks okay.
And I realised that the topics being taught probably don’t belong as database rows. Using a file is solidly superior. And syncing a file into a database row is needless complexity.
So let’s look at how to use file-based models to do this. It turns out to be basically the right solution to this problem, it’s underused, and as a topic it matches a chapter from my Rails book. Perfect.

It’s possible to use ActiveModel to get ‘normal’ Rails model functionality in somethat that isn’t a database class. ActiveModel provides callbacks, lets you inflect names to make them singular or plural, allows ActiveRecord-style validations and many other things. It doesn’t do anything I really want for this case, though, so I’m skipping it for now. It would be easy enough to add later if I want it.
Replacing ActiveRecord with Structs
Most of switching from ActiveRecord to Plain Old Ruby Objects (POROs) is easy enough. Parsing JSON is trivial. Having a topic contain a “steps” field is easy. I can manually check the JSON’s structure easily. I could even use a heavyweight schema validator if I needed something complicated. I don’t think I do, though.
One minor difficulty is that I’d like to keep saying “step.desc” rather than “step[:desc]”. For that, Ruby Structs are a good simple solution. It turns out some variations like OpenStruct are quite slow, but I just need plain old Struct for what I’m doing.
One thing databases do well is synthetic IDs. When you put information into a database row, you normally tag it with a simple, unique, easy-to-check integer primary ID. You can refer to that information with that ID from then on. In my JSON files I don’t get that automatically.
The reason synthetic IDs matter is because I’m already using the Step IDs to track what user has completed a particular step. Instead of trying to mimic what databases do with globally-unique incrementing integers, I’m going to change the completion’s step ID to a string, which will be easier for me to track in JSON files.
Another thing databases do well is live data loading. I don’t need to do as well as databases for this - for v1 I should either load every time, or load once on startup. Having to restart the server to update topics will eventually be a hardship, but I’m nowhere near that yet. And file modification dates mean that it’s not hard to build live reloading with files either.
And finally, Rails tracks timestamps (createdat and updatedat) automatically for DB rows. For a file I have to do that myself. It’s not hard. Files have creation and modification timestamps too.
I’ve written up three topics as JSON with real blog posts and videos. That gives me a nice place to start. Here’s an excerpt:
{
"name": "Coding Studies",
"desc": "This topic is about coding studies: a specific coding practice exercise. First you'll learn how to do them, then see some coding studies in action.",
"thumbnail_url": "/img/rms_thumb_flask.png",
"data": {
"related": ["software_practice"],
},
"steps": [
{
"name": "Conscious Coding Practice: the Three Concrete Steps",
"id": "rubyconf-conscious-coding-practice",
"type": "video",
"desc": "Coding studies are a specific coding practice exercise, stolen from a profession with a lot more teaching experience than we have. This forty-minute video tells you the what, why and how.",
"data": {
"video": { "youtube": "33fAzjOTaDE" }
}
},
{
"name": "A Simple Coding Study: Ivy on a Windowsill",
"url": "https://codefol.io/posts/a-simple-coding-exercise/",
"id": "a-simple-coding-exercise",
"type": "blog",
"desc": "Here's a simple example of how to look at something in the real-world, like an artist, and mimic the interesting features to get better at coding.",
"data": {
}
}
]
}
Since some of this is text and some video, I’ve started using a “type” for each step, which can be “blog”, “video” or “blogandvideo”.
Schema, Schema, Schema
I can do a rough-and-ready conversion of the Topic class from database models to file models and things should mostly still display well. So let’s do that.
While I could use the Struct class directly like an ActiveRecord type, I’m a little leery of that. I have constants that need to be declared before I can create the struct type, for instance, and a combination of methods on instances and methods on the class itself. I decide to just create a Topic type that includes a wrapped TopicStruct type and StepStruct type. You can see the full diff here, but here’s the relevant excerpt:
class Topic
def self.all
root_path = File.join(TOPIC_ROOT, "*.json")
objs = Dir[root_path].map do |topic_file|
load_topic_from_json(File.read(topic_file), created: File.ctime(topic_file), updated: File.mtime(topic_file), id: File.basename(topic_file, ".json"))
end
objs
end
def self.find(topic_id)
filename = File.join(TOPIC_ROOT, "#{topic_id.downcase}.json")
load_topic_from_json(File.read(filename), created: File.ctime(filename), updated: File.mtime(filename), id: topic_id)
end
def self.load_topic_from_json(json_string_data, created:, updated:, id:)
raw_objs = JSON.load(json_string_data)
illegal_keys = raw_objs.keys - TOPIC_KEYS.map(&:to_s)
raise("Illegal keys in topic: #{illegal_keys.inspect}!") unless illegal_keys.empty?
steps = raw_objs["steps"].map do |step_objs|
unless STEP_TYPES.map(&:to_s).include?(step_objs["type"])
raise("Illegal type #{step_objs["type"].inspect} for step object!")
end
StepStruct.new name: step_objs["name"],
desc: step_objs["desc"],
url: step_objs["url"],
id: step_objs["id"],
type: step_objs["type"],
data: step_objs["data"]
end
TopicStruct.new name: raw_objs["name"],
desc: raw_objs["desc"],
thumbnail_url: raw_objs["thumbnail_url"],
data: raw_objs["data"],
steps: steps,
id: id,
created_at: created,
updated_at: updated
end
end
That’s not terrible. A bit verbose, but not complicated. We also need to drop the Steps and Topics tables and change the UserStepItem to use a string for the step ID. And we prepend the Topic ID to the step ID so we don’t have to make them globally unique. But it turns out the JavaScript we wrote already treats the step ID as an opaque string (nearly - and it’s an easy fix), so the whole change isn’t too bad.
It’s reminding me that this is big and sprawling enough to need tests again, though. Some of the things I’m seeing are hard to test, but many aren’t too bad and I should be testing them.
Showing the Steps
Currently we’re not displaying some of the nice useful data in the JSON file. We’re not showing videos at all, for instance. Let’s show off some of that writing.
That brings us to the question, “how will I turn that freeform JSON field into interesting HTML that a learner can interact with?”
It’s generating HTML, which suggests not using model or controller code for it. But it’s deeply entwined with the business logic in the model. What’s the answer here?
One possible answer is “helper.” Another is something more exotic like a decorator or presenter — something that does nontrivial logic to turn model-specific data into presentation to the user. Those are mostly the same answer, in that a decorator or a presenter is basically a helper method that has grown large enough (and/or has enough internal state) to merit its own object.
In fact, I had just about convinced myself that I should write a complex presenter/decorator type and instance and dispatch on it… when I looked at the code and thought, “this could also be three partials, and another partial that dispatches to one of them based on the type field.”
Sigh. Being a responsible adult engineer sucks, as the Foglios remind us frequently:

I feel like these guys would make good software developers.
So, those partials. I figure it makes sense to have a top-level ‘master’ partial dispatching to three (for now) others. Simple enough:
# topic.rb
PARTIAL_BY_TYPE = {
"blog" => "step_blog",
"video" => "step_video",
"blog_and_video" => "step_blog_and_video",
}
// topics/_step.html.erb
<% partial_name = Topic::PARTIAL_BY_TYPE[step.type] %>
<%= render "topics/#{partial_name}", step: step %>
// topics/_step_blog_and_video.html.erb
<h3><%= step.name %></h3>
<p><%= step.desc.html_safe %></p>
<iframe width="560" height="315" src="https://www.youtube.com/embed/<%= step.data["video"]["youtube"] %>" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<p>
<a href="<%= step.url %>" target="_blank">🔗 Open Blog Post in New Tab 🔗</a>
</p>
This isn’t perfect visually, but it’s doing the right thing - showing a different layout for the different types, using a different partial for each. And I’d rather edit a partial full of markup than Ruby code generating that markup any day of the week. This is much simpler than using decorators, and easier to modify.
You can also see the full commit on GitHub as usual.
Here’s what it looks like:
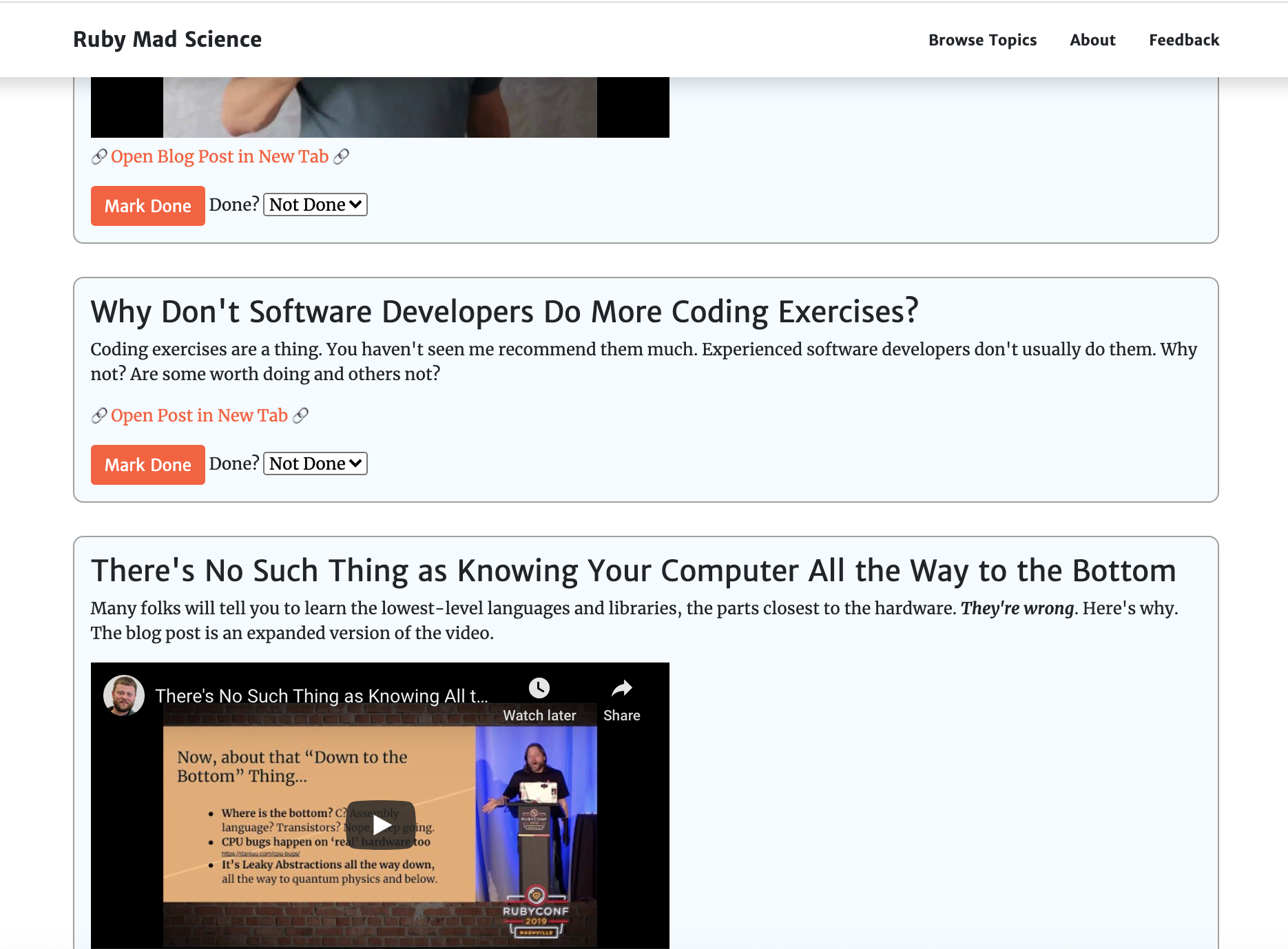
Moving Right Along…
I’m really happy with how this looks. I have three real topics there and it’s not too painful to write new ones — much better than calling Step.create manually in the Rails console!
There’s really only one piece of functionality left before I can let people use this: email reminders! I’m kind of dreading them, honestly, but I think they’re really important. That’s the kind of thing I often dread.
Want to see more about Ruby Mad Science as it happens? You can check the rubymadscience tag on this blog, including not-yet-published ones. There’s also an RSS feed of posts at the top, or you can subscribe to my email list below. I’ll definitely email the list with these posts.
Or if you’ve bought one of my books, you get to read and discuss blog posts early with my readers as I finish them, in the #prerelease-blog-posts channel of the customer Slack.

Comments